LOL charsets
¶ by Rob FrieselOr: an almost certainly incomplete but hopefully accurate enough (and succinct) front-end developer’s guide to charsets and character encoding.
Before we begin, I will summarize the problem with the following picture:
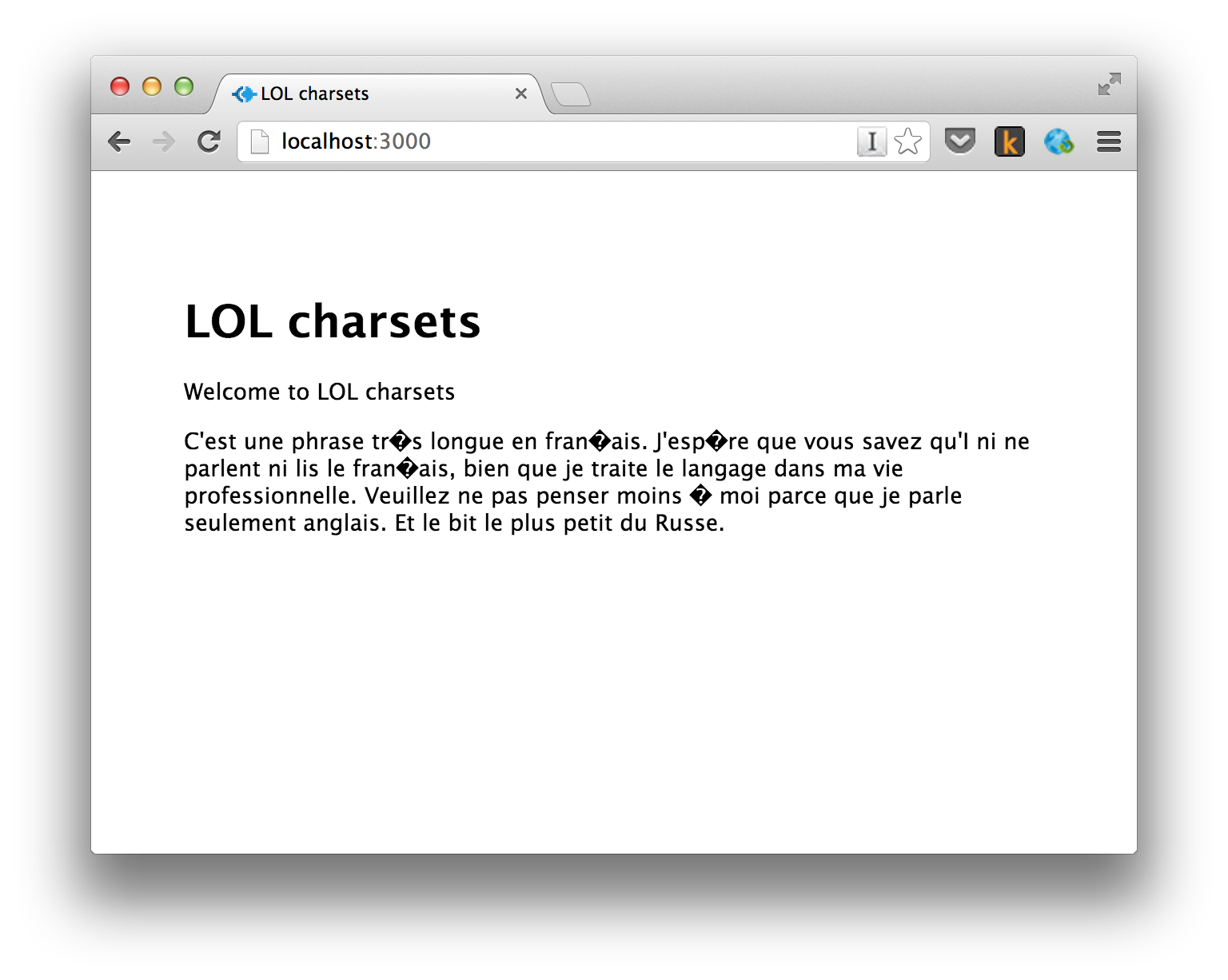
Do you see those funny diamonds with the question marks in them? That’s about the size of the problem, right there. 1 You have some text for your French-speaking customers, but without the right instructions the computers between you and your customers are too stupid to know that some series of numbers are going to need to display as a ç and not as… something unattractive.
Now, before we get in to any of the details, here’s the spoiler alert for the rest of this post: Just pay attention to the charset(s) that you use — those are the “rules” for how your computer (and every other computer) is going to convert “the numbers” into “the letters”. Remember to be explicit about which charset to use (the whole way down the line!) and hopefully you can save yourself a little embarrassment and frustration.
I won’t pretend to be an expert on the subject. Smarter people than I have written more extensively about this; perhaps the canonical post on the matter of charsets and encoding turns 10 years old this year: Joel Spolsky’s seminal “The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)”. 2 3 I do not endeavor to re-hash Spolsky’s post, 4 but what I do hope to deliver here is a kind of checklist — a field guide for front-end developers re what to look at while developing (or debugging) your application and the perils of internationalized text.
We’ll start in the back and work our way to the front.
A crash course in charsets.
Before we dive in to the field guide, let’s set up a libretto for what we mean when we talk about “charsets”. Imagine trying to explain how “text works on computers” to your grandparents or to your recluse cousin that lives in deepest rural North Dakota. The explanation might sound something like this:
- The computer has a series of binary digits (
0s and1s 5) that - get converted into hexadecimal digits (
0-9plusa-f) - which are in blocks of four (or eight (or two (or…?)))
- which are translated to a code point (like coordinates on a map)
- that tell the computer which letter to use when it sees that number.
And this is to say nothing at all of the other manipulations that any renderers may perform on the letter w/r/t/ typeface, size, weight, embellishments, color, etc. Everybody understand “plain text” now? Good. Let’s start debugging examining our system!
What’s on disk?
First: what is the character encoding on the disk? By “on disk” I mean the literal storage media: hard disks, databases, properties files, etc. Any place where your text is going to be persisted in such a way that it will survive a loss of power. What instructions did that application receive w/r/t/ persisting your text? In my experience, most modern applications default to UTF-8; also (fortunately?) in my experience, most modern applications are pretty smart about automatically detecting the encoding, and using that when performing their “save” operations.
What’s going over the network?
Second: what charset are you telling your application to use when sending the bits over the wire? This one is especially important and I’ll explain why in a little bit. Of particular interest to you is going to be the Content-Type header in the HTTP response. (If you don’t know how to find/inspect these headers, may I suggest familiarizing yourself with Firebug’s Network tab and/or the Network panel in Chrome Dev Tools. 6) You should see something like this in the response headers:
Content-Type: text/html; charset=UTF-8
…although the charset piece may be missing, depending on your server and/or the web app serving your content.
Why did I say that this was especially important? Because the W3C spec says that the HTTP Content-Type header takes precedence; when the browser receives your resource, it needs to interpret the bits and bytes according to the charset specified in the HTTP header. If that header is there, no other specified charsets matter.
What does your resource say?
If the Content-Type header is missing the charset declaration, then the client has two options left to sort out how to convert “the numbers” into “the letters”. The first one is an explicit pragma in the resource that you sent. What encoding are you telling the browser to use? If you know that your server is not specifying a charset, or if you are otherwise unsure, you can make the suggestion right there in your HTML document:
<!-- the "HTML4" way: -->
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<!-- the "HTML5" way: -->
<meta charset="UTF-8">
Look familiar?
In the “HTML4 way” example: The http-equiv attribute is telling the document which HTTP header it is standing in for; the content attribute specifies the value (in this case text/html; charset=UTF-8). In the “HTML5 way” the meta tag is much simpler: we simply specify the charset and move on.
Again: in both cases, the meta tag amounts to little more than a suggestions. Remember: the HTTP Content-Type header takes precedence over anything you might declare in the document itself.
What does your browser/client think?
Lastly: if your client (e.g., the web browser) is given no instructions (i.e., no Content-Type header, and no meta equivalent), then it will try to sort out the encoding on its own. This quickly gets… complicated. In my experience, most browsers do a pretty good job of figuring out which charset to use when they’re in “Auto Detect” mode. 7 But… Did you leave it in “Auto Detect”? Or did you override that setting at some point and forget to put it back?
To make matters more complicated: a page delivered with no charset specified in the Content-Type header and no meta equivalent might work perfectly fine “on its own” but then get misinterpreted when it is delivered into an iframe that is embedded in a parent document that has a conflicting charset. For example: if you have a “top level” page that is explicitly using UTF-8 (e.g., from its Content-Type header) and it frames in another page that is only implicitly encoded as ISO-8859-1 (e.g., it is that way “on disk” but is missing the charset declaration from both the Content-Type and has no meta equivalent), most browsers will look up to the “top level” parent page and use that encoding on the “child” page.
But you as a front-end developer don’t have any control over your customer’s machines (or your customer’s customer’s machines…) — and so why even bring this up? Partly as a caution, and partly to provide a more complete picture on the subject.
What else do you need to consider?
The short answer? You should consider everything that might touch your characters. Seriously. Anything that might touch your characters should be examined to ensure that it’s respecting the charset that you’re setting. An incomplete list of seemingly innocuous tools and processes that could wreck havoc on your numbers-to-letters conversions:
- Converters. Example: let’s say you keep your text in a properties file and then build JSON bundles for your front-end text. How are your strings getting converted? Does your converter know which charset to use when reading the properties files? And what charset does it use when it writes the bits back out?
- Templates. Maybe this overlaps with the “Converters” bullet above but… What about your web app’s templates? Sure, the template’s source is UTF-8 on disk, but does the template engine know that it needs to be UTF-8 when the processing is finished?
- Filters and instrumentation. Do you have any filters or instrumentation code that’s intercepting your HTTP responses? What’s it doing? Is it rewriting the character encoding in the output stream? And even if it leaves the payload alone… what about the charset declaration in the
Content-Typeheader? - CDNs. Do you put any of your static content on a CDN? Is the CDN delivering those assets with the right encoding?
Can you think of any other players that might be interfering?
Keep it clean.
As you can see, there are plenty of places in the chain where your charsets can break down — and in a big enough application, you will eventually see every single one of these problems: someone will save the properties files in the wrong encoding; someone will put a filter in place that doesn’t account for the charsets; someone will change the Content-Type header; etc. Hopefully, armed with a checklist like the above, you can more quickly chase down the source of your charset woes. Instead of spending two miserable days wondering why half your accented characters are all of the sudden and inexplicably turning up as hideous question marks.
![I [mark] Unicode](http://blog.founddrama.net/wp-content/uploads/2013/01/i-mark-unicode.jpeg)
- If you are interested in the technical details behind the example: that page is being served by a simple Express.js app with a
Content-Typeheader that specifiestext/html; charset=UTF-8, but the file itself (an EJS template) is saved to disk as ISO-8859-1 (Latin-1). And TJ-only-knows what happens in the conversion process between when the route passes the model to the template and when the generated mark-up actually goes out as the body of the request. (And yes, I intentionally created the charset mis-match for illustrative purposes.)[↩] - Seriously: if you haven’t already read it, go read it now. I’ll still be here when you get back. Read it yet? Go! Now! (No excuses!)[↩]
- Also: Jeff Atwood’s follow-up post on Coding Horror is good, too.[↩]
- Did you read it yet? Seriously, because that history of encoding is fascinating and there’s no way I could top that.[↩]
- ”Why?” Because ultimately that’s how computers do everything.[↩]
- If you’re using Opera: I think Dragonfly has something for this, but I have not spent
muchany time with it. And if you’re using Internet Explorer… sorry you’re on your own here.[↩] - Again: check out Spolsky’s post about this. Lengthy case-in-point:
Internet Explorer actually does something quite interesting: it tries to guess, based on the frequency in which various bytes appear in typical text in typical encodings of various languages, what language and encoding was used. Because the various old 8 bit code pages tended to put their national letters in different ranges between 128 and 255, and because every human language has a different characteristic histogram of letter usage, this actually has a chance of working. It’s truly weird, but it does seem to work often enough that naïve web-page writers who never knew they needed a Content-Type header look at their page in a web browser and it looks ok, until one day, they write something that doesn’t exactly conform to the letter-frequency-distribution of their native language, and Internet Explorer decides it’s Korean and displays it thusly, proving, I think, the point that Postel’s Law about being “conservative in what you emit and liberal in what you accept” is quite frankly not a good engineering principle.
[↩]
Leave a Reply