git cherry-pick: it might not be what you think
¶ by Rob FrieselAmong the myriad of powerful features in Git, cherry-pick is probably the cause of and solution to most of my source control problems. I use it often, and probably way more than I should; I say the former because it seems like the obvious way to selectively and surgically move around “just those” changes, and the latter because the temptation to use cherry-pick is strong, and it’s easy to forget that there is some peril hidden in there as well.
cherry-pick: a short definition
If you don’t know what Git’s cherry-pick is, here is a definition from the man page’s description:
Given one or more existing commits, apply the change each one introduces, recording a new commit for each.
It does what it says on the tin: it “cherry picks” changes from one branch to another. In plain English, use it like this:
- Check out the target branch. (For example:
master.) - Run
cherry-pickand give it the SHA for the commit that you want to bring in to that branch.
(“Real” sample commands later on.)
As I mentioned, I often run in to cases where cherry-pick seems like the perfect solution. For example, working on a topic branch, I identify an existing defect, patch it, and then immediately cherry-pick it across to develop or master 1 so it can get integrated before the rest of the topic branch. 2 Or (variation on the previous) a subset of features/changes from a topic branch need to get integrated before the rest of the topic branch.
Generally speaking, these are the kinds of places where cherry-pick seems to fit the bill nicely.
But…
But these are also the places where cherry-pick is likely to bite you. Why? Let’s look at that definition again:
Given one or more existing commits, apply the change each one introduces, recording a new commit for each.
That’s right. cherry-pick introduces a new commit. Same change, different commit. If you’re throwing away the rest of the topic branch, this isn’t a big deal — cherry-pick to your heart’s content! But if you’re planning on integrating that topic branch later, you could be in for some problems.
Example
Let’s take a look at a scenario where cherry-pick might give us some heartache. Imagine a repository with a master branch that has one commit on it.

A simple enough place to start.
Now let’s create a topic branch and start making our changes.
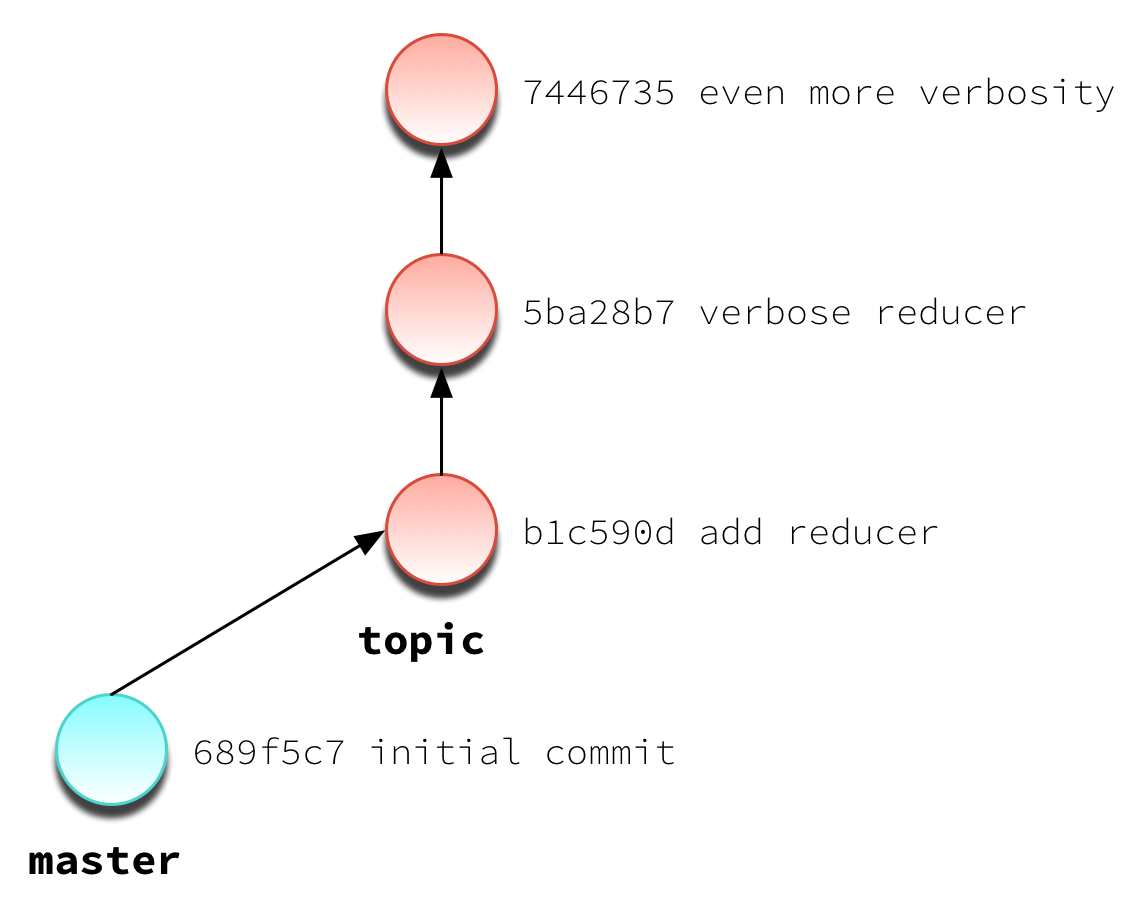
This should be pretty familiar. You’re plugging away at your development, making your commits as you go. Progress.
Now let’s assume that you need to get that first topic commit (b1c590d) onto master ahead of everything else. Naturally we think: cherry-pick!
And we get this:
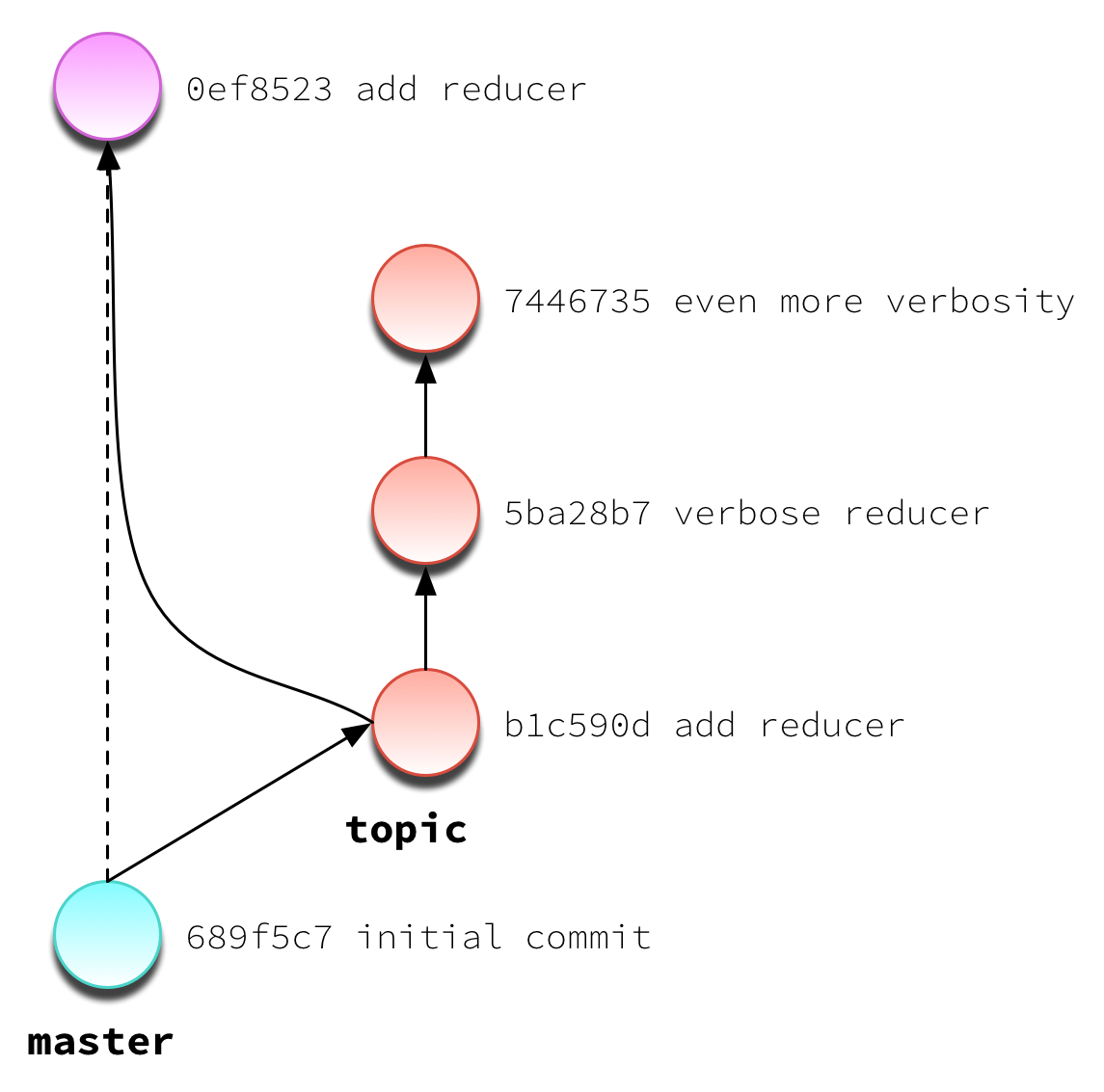
Hooray! Now master has the changes that we so urgently needed to incorporate. Now we can return to our topic branch and finish up those features. But when we perform our merge, we have conflicts:
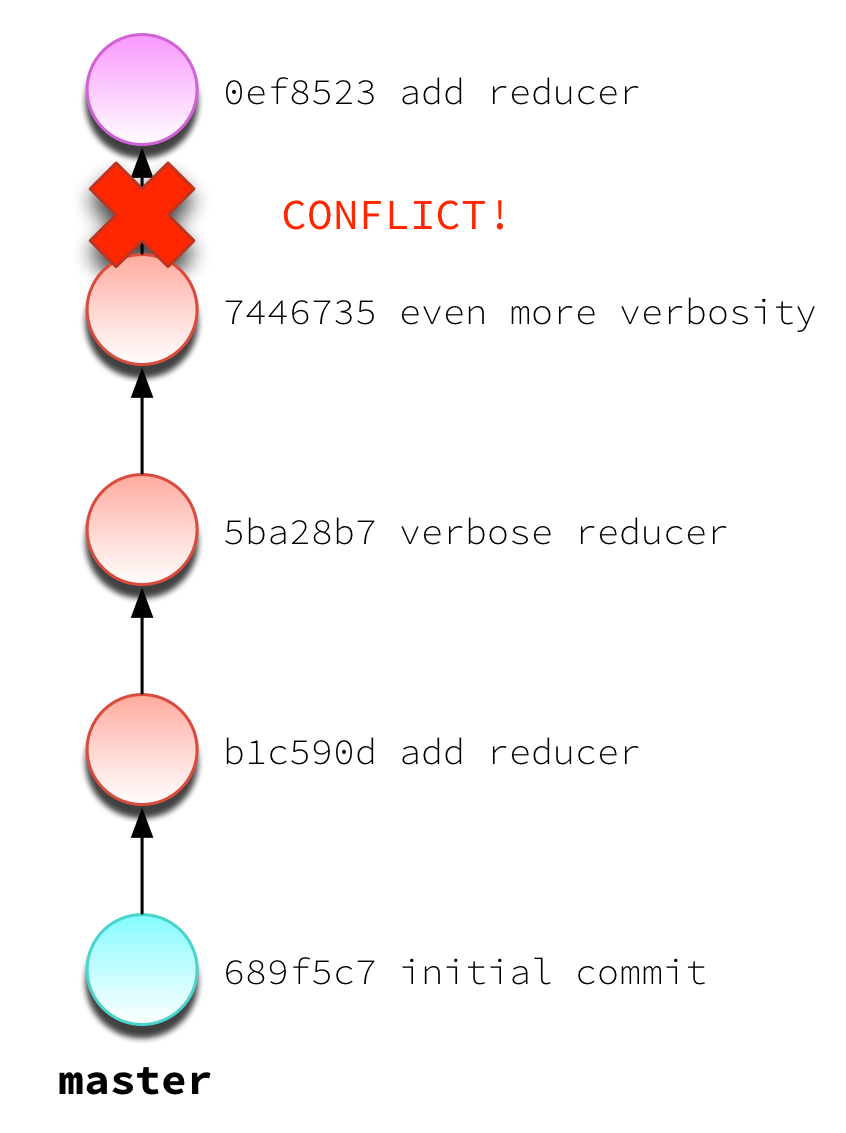
Remember that thing about “recording a new commit”? Yeah. That.
Luckily, in our contrived example, this merge conflict is trivial to resolve. But the your real world encounter with this probably won’t be so easy.
The Moral of This Story
When first learning about cherry-pick, don’t lose yourself in the excitement of being able to move copy those arbitrary commits. Remember that last bit in the description about the changes being recorded as a new commit. If you don’t read that part closely, it’s easy to believe that Git is going to recognize these commits as the same thing (in our example b1c590d and 0ef8523). 3 It doesn’t, but that’s because that (i.e., cases like the above example) isn’t what cherry-pick is for. Again: cherry-pick is really “for” the times when you’re going to throw away the topic branch and only keep a handful of the “salvageable” changes.
This isn’t to say that you can’t use cherry-pick for cases like the one in our example. Just be aware that you (and not Git) are on the hook for resolving those conflicts. They’re not guaranteed to happen, but there’s a strong possibility that it will. Instead of cherry-pick, consider other strategies. For example, if you identify a defect on the topic branch, instead of fixing it there and cherry-picking it back to develop, consider switching to develop or master, performing the fix on a separate topic branch, and then merging those changes to the places where you need them.
As I mentioned, cherry-pick is a powerful tool, but it has that one little quirk that can trip you up if you aren’t paying close enough attention. Use it, but use it well and wisely.
- And here I’m taking for granted that you’re using “Git Flow” or something like it. Be warned: I’ll probably lapse into that assumption a couple of times.[↩]
- And/but: “You really shouldn’t solve that problem that way…”[↩]
- I freely admit it: for the first year or so of using Git, I had come to that erroneous conclusion and made that mistake often. It took me a while to figure out why (a) I kept seeing the same changes twice in the log and (b) why I kept getting so many merge conflicts.[↩]
Leave a Reply